Memory and Functional Unit Design for Vector Microprocessors
This project aims to improve the energy efficiency of the next generation of high performance Arm processors (A15+).
The current focus is improving battery lifetimes under heavy workloads such as gaming and video streaming. In current systems the cost of moving data to the processor is approximately 100,000 cycles from mass storage (hard disks), 250 cycles from main memory, 10-15 cycles from level 2 cache and 1-2 cycles from level one cache. This project aims to improve the efficiency and speed of the processor – L1 interface.
Techniques used are:
- Use of vectorization techniques; i.e. efficiently perform the same operation at multiple data values at once (e.g. modify x pixels in parallel instead of 1 at a time)
- Improved processor to L1 interface to allow multiple parallel accesses in an energy efficient manner
- Exploitation of memory access patterns to re-use memory address translation results and simplify comparator structures
- Reduce number of cache line conflicts (two cache accesses to the same line blocking each other)
- Try to re-use L1 data to service multiple reads to the same cache line
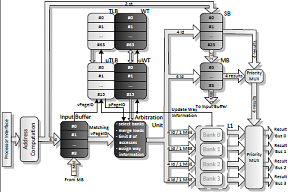
Multiple Access Low Energy Cache Interface
US Patent filed (Ref.: P100014US RJB LAH)